Domain-Driven Design, part 3 — Simplify Object Model
There are always many ways how to implement the abstract model. The implementation can be made in smooth and simple or in over-complicated way. It is surprisingly easy to end up with a complicated solution.
But we will take the effort and introduce strategies and concepts that will help us simplify the model.
Model
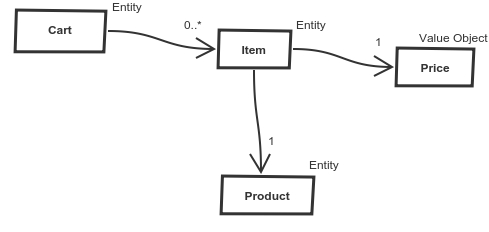
It doesn’t make sense to explain modeling on Foo, Bar, etc…, the Domain-driven design is about the domain. Let’s use an e-shop cart model from the previous article.

Concrete Associations
Associations between objects are naturally two-ways. But it’s really difficult to think, work and program with two-ways associations. We try to simplify them if it’s possible.
A product is something that our customers buy. Does the product know about an item in cart? No way, the product has no idea about the cart at all. This association can be one-way, hooray!
We can imagine the price as a sticker on the product. The sticker is on the product and of course, the product is labeled with the sticker. But does the price sticker care where is it stuck? No, price doesn’t care where it is, so this association can be also one-way.
And now the associations between cart and item. The cart can hold more items, so this association is the first that allow multiplicity. Does item care where it is? In which cart? No, so the last association can be one-way too.

The cart example is pretty straightforward, but in our future work, we can find associations which are two-ways. Two-way association is difficult to maintain and we should use it only where it is absolutely necessary.
Entities
Who am I? I’m a unique person. I can cut my hair, change a name if I marry, or have an accident and my body shape might change. My look might change, people might call me differently, but it is still me. It is my identity what identifies me, nothing else.
Entities have the same story. They are unique in the system and if their properties changes, they are still the same entities.
Identity
An entity is identified by an identity. This has some practical consequences. A unique entity must be only one in the system, stored as one piece of memory. When we compare entities, we have to compare only their identities. If the identity is same, the entity is same.
Cart Entities
A cart — if we add a product, is it still the same cart? It is. Entity.
A product — let’s assume, a product is an entity, and keep focus on the cart.
A price — if we change the price value, is it the same price? No, it becomes a different price. So the price is not an entity.
An item — item holds information about a product amount. If we change the amount, does it represent the same cart item? Maybe yes, maybe no. Now we should discuss with a domain expert to deepen our domain knowledge. If the answer is not clear we have to choose by ourselves and maybe change this decision later. For now, we decide that an item is an entity identified by product.

Value Objects
We have to paint a room, what do we need? A paint of a given color. While we are painting we do not care which drop of paint is where, as long as we have enough paint we are able to finish the job. And if we spill a can, we can replace it with a new one without noticing a difference.
Value objects represent objects without identity.
As well as paint is identified by its color, a value object is identified by all of its properties. If two value objects have the same properties, we are not able to distinguish them, they are identical for us. Thanks to this property we do not care which instance we are using unless it has the right properties.
Value objects are immutable, side-effect free and easier to understand than entities. We are not able to change value object properties, instead of that we have to create always a new one. Immutability allows us also to share value objects over the whole system and save memory if necessary.
Identity and identifier
Entities are identified by an identity. How do we select an entity from a collection? We need a tool which also identifies entity, and that tool can be an identifier.
An identifier can be a practical implementation of an identity. Identifier as a value object really fit — if any property of an identifier is different, the identifier is different. If all attributes of the identifier are the same, it is the same identifier.
Cart Value Objects
The price is a typical value object in a cart model. It represents how much does the item cost and is identified by its value.
Aggregates
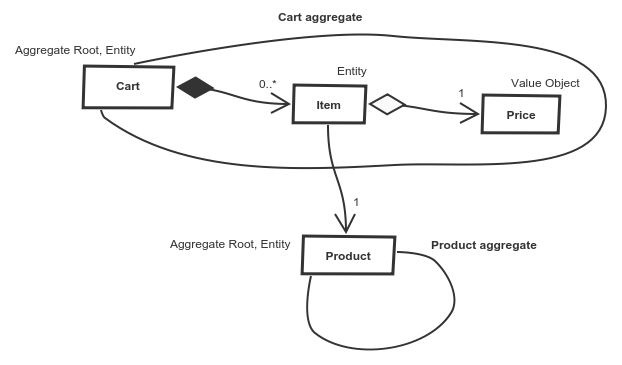
An aggregate is a group of objects that live and die together. Aggregate parts do not make sense without each other, they make sense only if they are all together.
We cannot access inner objects of an aggregate from outside, we have to use the main object always, so-called aggregate root. Aggregate is an encapsulated single unit (OOP starts to make sense!). Thanks to the encapsulation, it is easy to understand the aggregate and it is also easy to refactor the internal structure of aggregate.
Cart Aggregates
A product is a thing in which are our customers interested in. We would just say it is an aggregate.
Can the item live without a cart? Nope, because logic is in both of them, in the cart itself and also in items.
What about the price? Does price make sense without the item? Well maybe yes. And does the item make sense without the price? No, the item must have its price.
The cart, items and the price are the aggregate. The cart is also a natural entry point, the aggregate root. This helps us to encapsulate item concept for cart user, so the cart is easier to be understood. Encapsulation also strengthens the association between cart and item. It can be a composition now because cart owns items.
Separated aggregates
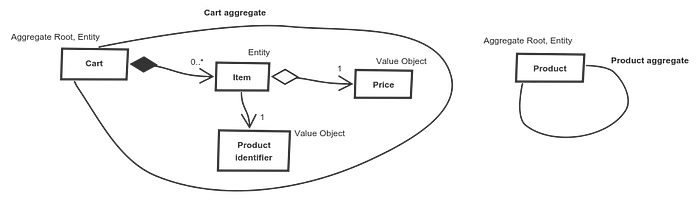
Aggregates must be understood whole or not be understood at all, must be created wholly or not be created at all, must be persisted whole or not be persisted at all, must be received from a repository (database or any storage) whole or not be received at all.
Right now we have a problem with a cart and a product. We cannot work with a cart without associated products.
What is an item responsibility? It holds the product amount, the price and is identified by the product. What does it need from the product? Only the product identifier. Why does it have to know about the whole product? It doesn’t. Great, we just separated aggregates!
Benefits
- Easy to understand
- Easy to test
- Easy to persist
Problems
What about the data integrity? What happens if we delete a product? It doesn’t have to be a problem — we don’t have a delete use case, so in this system, it cannot happen.
But anyway, whose responsibility is the data integrity? Should the product deal with it? Should the cart deal with it? No way, the product is something that people buy and the cart is a box.
We can create a domain service that looks for carts that contain a given product identifier. If it finds at least one, it doesn’t allow to delete a product.
We can deal with these use cases in an infrastructure — we can define foreign keys in a database. But this solution has also some issues. It is difficult to test, it relies on infrastructure and nobody says that product and cart are in the same database.
TL;DR
The model can be simplified by concreting associations, identifying entities, value objects, and aggregates. Aggregates can be separated to be easy to understand, implement and test.
Next time we’ll implement the cart model.
References
EVANS, Eric. Domain-driven design: tackling complexity in the heart of software. Boston: Addison-Wesley, 2004. ISBN 0–321–12521–5.
БУГАЕ́НКО, Его́р. Objects Should Be Immutable. Yegor’s Blog About Computers [online]. 2014 [2017–12–13]. Available: http://www.yegor256.com/2014/06/09/objects-should-be-immutable.html
VERNON, Vaughn. Implementing domain-driven design. Upper Saddle River, NJ: Addision-Wesley, 2013. ISBN 978–0–321–83457–7.
Contact
Are you designing architecture and like DDD approach? Hire me, I can help you — svatasimara.cz
